一、基础环境准备:
1、Linux服务器安装时间服务器,同步时间:
1、用 ntpdate从时间服务器更新时间:
yum -y install ntp
2、编辑 ntp.conf 文件
vim /etc/ntp.conf
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
server ntp4.aliyun.com iburst
3、设置系统时间为北京时间:
timedatectl set-timezone Asia/Shanghai
4、重启ntp服务、开机自启:
systemctl start ntpd
systemctl enable ntpd
5、测试:
date #查看返回的时间时候正常
ntpdate time.nist.gov
date #再查看时间是否同步
2、Linux服务端、客户端要安装docker、docker-compose服务:
1、安装docker:
1、更新系统:
yum update -y
2、安装docker ce 所需的软件包:
yum install -y dnf-plugins-core
3、添加docker-ce.repo源:
yum config-manager --add-repo=https://repo.huaweicloud.com/docker-ce/linux/centos/docker-ce.repo
4、将docker-ce.repo中官方地址替换为华为开源镜像,提升下载速度:
sed -i 's+download.docker.com+repo.huaweicloud.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
sed -i 's+$releasever+8+' /etc/yum.repos.d/docker-ce.repo
5、重新加载缓存:
yum makecache
6、安装docker-ce:
yum install -y docker-ce docker-ce-cli containerd.io
7、添加镜像加速:
mkdir -p /etc/docker
tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://代理地址,网上自己搜"
],
"insecure-registries": [
"192.168.188.251:8081"
]
}
EOF
8、启动docker服务,并设置开机自启:
systemctl start docker && systemctl enable docker
systemctl status docker
systemctl restart docker
9、查看dokcer版本:
docker version
2、安装docker-compose:
1、安装docker-compose:
yum install -y docker-compose-plugin
2、查看docker compose 版本:
docker compose version
二、服务端:
1、将 GitHub 上的代码克隆到 Linux服务端 的服务器上:
git clone https://github.com/zorn-zhao/docker-prometheus.git
2、修改 docker-compose.yml文件:
vim /root/docker-prometheus/docker-compose.yml
version: '3.3'
volumes:
prometheus_data: {}
grafana_data: {}
networks:
monitoring:
driver: bridge
services:
prometheus:
image: zorn0zhao/prometheus:v2.53.1
container_name: prometheus
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- $PWD/prometheus/:/etc/prometheus/
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
networks:
- monitoring
links:
- alertmanager
- cadvisor
- node_exporter
expose:
- '9090'
ports:
- 9090:9090
depends_on:
- cadvisor
alertmanager:
image: zorn0zhao/alertmanager:v0.27.0
container_name: alertmanager
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- $PWD/alertmanager/:/etc/alertmanager/
command:
- '--config.file=/etc/alertmanager/config.yml'
- '--storage.path=/alertmanager'
networks:
- monitoring
expose:
- '9093'
ports:
- 9093:9093
cadvisor:
image: google/cadvisor:v0.33.0
container_name: cadvisor
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
networks:
- monitoring
expose:
- '8080'
node_exporter:
image: zorn0zhao/node_exporter:v1.8.2
container_name: node-exporter
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.ignored-mount-points'
- "^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/aufs)($$|/)"
networks:
- monitoring
expose:
- '9100'
grafana:
image: grafana/grafana:7.1.5
user: "104"
container_name: grafana
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- grafana_data:/var/lib/grafana
- $PWD/grafana/provisioning/:/etc/grafana/provisioning/
env_file:
- $PWD/grafana/config.monitoring
networks:
- monitoring
links:
- prometheus
ports:
- 3000:3000
depends_on:
- prometheus3、修改 alertmanager告警 的配置文件:
vim /root/docker-prometheus/alertmanager/config.yml
global:
#163服务器
#smtp_smarthost: 'smtp.qq.com:465'
smtp_smarthost: 'smtp.163.com:25'
#发邮件的邮箱
#smtp_from: '[email protected]'
smtp_from: '[email protected]'
#发邮件的邮箱用户名,也就是你的邮箱
#smtp_auth_username: '[email protected]'
smtp_auth_username: '[email protected]'
#发邮件的邮箱密码 这儿的密码是第三方授权码
#smtp_auth_password: 'your-password'
smtp_auth_password: 'xxxxxx'
#进行tls验证
#smtp_require_tls: true
smtp_require_tls: false
route:
group_by: ['alertname','instance']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: 'default'
routes:
- match_re:
instance: "172.30.225.112:39100|172.30.225.115:39200"
receiver: 'test员工'
- receiver: 'other'
receivers:
- name: 'test员工'
email_configs:
- to: '[email protected]'
- name: 'other'
email_configs:
- to: '[email protected]'
- name: 'default'
email_configs:
- to: '[email protected]'
# 抑制规则
# inhibit_rules:
# - source_match:
# alertname: 高负载警告
# severity: critical
# target_match:
# severity: normal
# equal:
# - instance
# 抑制规则
# 减少重复警告,如果同1台机器在短时间内多次触发相同的 高负载警告 的 警告 级别告警,只会发送1次,后续的相同告警将被抑制。这有助于减少告警风暴,避免重复告警对接收者造成干扰
inhibit_rules:
- source_match:
alertname: 高负载警告
severity: '警告'
target_match:
severity: '警告'
equal: ['alertname', 'instance']4、修改 prometheus中的 alert.yml prometheus.yml文件:
vim /root/docker-prometheus/prometheus/alert.yml
groups:
- name: 服务器状态
rules:
# Alert for any instance that is unreachable for >2 minutes.
# 服务器已掉线报警
- alert: 服务器已掉线
expr: up == 0
for: 2m
labels:
severity: 警告
annotations:
summary: "服务器 {{ $labels.instance }} 已掉线"
description: "{{ $labels.instance }} 服务器 {{ $labels.job }}掉线超过2分钟 "
# Windows 服务器CPU使用率
- alert: Windows服务器CPU使用率-90
expr: 100 - (avg by (instance) (rate(windows_cpu_time_total{mode="idle"}[2m])) * 100) > 90
for: 2m
labels:
severity: 严重
annotations:
summary: Windows 服务器 CPU 使用率 (instance {{ $labels.instance }})
description: "CPU 使用率已超过 90%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
# Windows 服务器内存使用率
- alert: Windows服务器内存使用率-90
expr: 100 - ((windows_os_physical_memory_free_bytes / windows_cs_physical_memory_bytes) * 100) > 90
for: 2m
labels:
severity: 严重
annotations:
summary: Windows 服务器内存使用率为 (instance {{ $labels.instance }})
description: "内存使用率超过 90%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
# Windows 服务器磁盘使用率
- alert: Windows服务器磁盘使用率-90
expr: 100.0 - 100 * ((windows_logical_disk_free_bytes / 1024 / 1024 ) / (windows_logical_disk_size_bytes / 1024 / 1024)) > 90
for: 2m
labels:
severity: 严重
annotations:
summary: Windows 服务器磁盘使用率为 (instance {{ $labels.instance }})
description: "磁盘使用率超过 90%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
# Windows 服务器磁盘使用率
- alert: Windows服务器磁盘使用率-95
expr: 100.0 - 100 * ((windows_logical_disk_free_bytes / 1024 / 1024 ) / (windows_logical_disk_size_bytes / 1024 / 1024)) > 95
for: 2m
labels:
severity: 严重
annotations:
summary: Windows 服务器磁盘使用率为 (instance {{ $labels.instance }})
description: "磁盘使用率超过 95%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- name: Linux 服务器状态
rules:
# CPU使用率告警
- alert: cpu使用率告警-80
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 80
for: 2m
labels:
severity: 警告
annotations:
description: "服务器: CPU使用超过80%!(当前值: {{ $value }}%)"
# CPU使用率告警
- alert: cpu使用率告警-90
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 90
for: 2m
labels:
severity: 严重
annotations:
description: "服务器: CPU使用超过90%!(当前值: {{ $value }}%)"
# 内存使用率告警
- alert: 内存使用率告警-80
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 80
for: 2m
labels:
severity: 警告
annotations:
description: "服务器: 内存使用超过80%!(当前值: {{ $value }}%)"
# 内存使用率告警
- alert: 内存使用率告警-90
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 90
for: 2m
labels:
severity: 严重
annotations:
description: "服务器: 内存使用超过90%!(当前值: {{ $value }}%)"
# 磁盘告警
- alert: 磁盘告警-80
expr: (node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes * 100 > 80
for: 2m
labels:
severity: 警告
annotations:
description: "服务器: 磁盘设备: 使用超过80%!(挂载点: {{ $labels.mountpoint }} 当前值: {{ $value }}%)"
# 磁盘告警
- alert: 磁盘告警-90
expr: (node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes * 100 > 90
for: 2m
labels:
severity: 严重
annotations:
description: "服务器: 磁盘设备: 使用超过90%!(挂载点: {{ $labels.mountpoint }} 当前值: {{ $value }}%)"
# MYSQL数据库监控规则
- name: MySQL数据库监控规则
rules:
# MySQL状态检测
- alert: MySQL Status
expr: mysql_up == 0
for: 10s
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} Mysql服务 !!!"
description: "{{ $labels.instance }} Mysql服务不可用 请检查!"
# MySQL连接数告警
- alert: Mysql_Too_Many_Connections
expr: rate(mysql_global_status_threads_connected[5m]) > 200
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 连接数过多"
description: "{{$labels.instance}}: 连接数过多,请处理 ,(current value is: {{ $value }})!"
# MySQL慢查询告警
- alert: Mysql_Too_Many_slow_queries
expr: rate(mysql_global_status_slow_queries[5m]) > 3
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 慢查询有点多,请检查处理!"
description: "{{$labels.instance}}: Mysql slow_queries is more than 3 per second ,(current value is: {{ $value }})"
vim /root/docker-prometheus/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 30s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 30s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "alert.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
# 抓取指标数据默认时间间隔是5s
scrape_interval: 30s
static_configs:
- targets: ['localhost:9090']
# 微商城主机
- job_name: '112mysql'
scrape_interval: 30s
static_configs:
- targets: ['172.30.225.112:39100']
- job_name: '115linux'
scrape_interval: 30s
static_configs:
- targets: ['172.30.225.115:39200']
# 内部linux主机
- job_name: '117linux'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.117:9100']
# - job_name: '117cadvisor'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.188.117:8080']
- job_name: '132linux'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.132:9100']
# - job_name: '132cadvisor'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.188.132:8080']
- job_name: '139linux'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.139:9100']
# - job_name: '139cadvisor'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.188.139:8080']
- job_name: '145linux'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.145:9100']
# - job_name: '145cadvisor'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.188.145:8080']
- job_name: '146linux'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.146:9100']
# - job_name: '146cadvisor'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.188.146:8080']
- job_name: '148linux'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.148:9100']
# - job_name: '148cadvisor'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.188.148:8080']
- job_name: '158linux'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.158:9100']
# - job_name: '158cadvisor'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.188.158:8080']
- job_name: '159linux'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.159:9100']
# - job_name: '159cadvisor'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.188.159:8080']
- job_name: '199linux'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.199:9100']
# - job_name: '199cadvisor'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.188.199:8080']
- job_name: '225linux'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.225:9100']
# - job_name: '225cadvisor'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.188.225:8080']
- job_name: '227linux'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.227:9100']
# - job_name: '227cadvisor'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.188.227:8080']
- job_name: '229linux'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.229:9100']
# - job_name: '229cadvisor'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.188.229:8080']
# 内部 Windows 主机
- job_name: '70windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.70:9182']
- job_name: '71windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.71:9182']
- job_name: '72windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.72:9182']
- job_name: '86windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.86:9182']
- job_name: '147windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.147:9182']
- job_name: '149windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.149:9182']
- job_name: '150windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.150:9182']
- job_name: '119windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.119:9182']
- job_name: '133windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.133:9182']
- job_name: '135windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.135:9182']
- job_name: '137windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.137:9182']
- job_name: '138windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.138:9182']
- job_name: '110windows'
scrape_interval: 30s
static_configs:
- targets: ['192.168.188.110:9182']
# 监控本地
# - job_name: 'cadvisor'
# Override the global default and scrape targets from this job every 5 seconds.
# scrape_interval: 5s
#static_configs:
# - targets: ['cadvisor:8080']
# - job_name: 'node-exporter'
# Override the global default and scrape targets from this job every 5 seconds.
# 抓取指标数据的时间间隔默认是5s
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
# scrape_interval: 5s
# static_configs:
# - targets: ['node_exporter:9100']
5、docker-compose 方式启动服务:
cd /root/docker-prometheus # (有 docker-compose.yml 文件的目录下部署服务)
docker-compose up -d # 启动服务
docker-compose stop # 停止服务
docker-compose down -v # 删除服务,先停止后才能删除
docker-compose restart # 重启服务,会重新加载配置文件
docker-compose ps # 查看服务是否正常启动
docker-compose ps -a # 查看服务是否正常启动
netstat -tlun | grep 8080 # 查看端口是否正常启动
netstat -tlun | grep 9100 # 查看端口是否正常启动6、grafana面板 添加仪表盘:
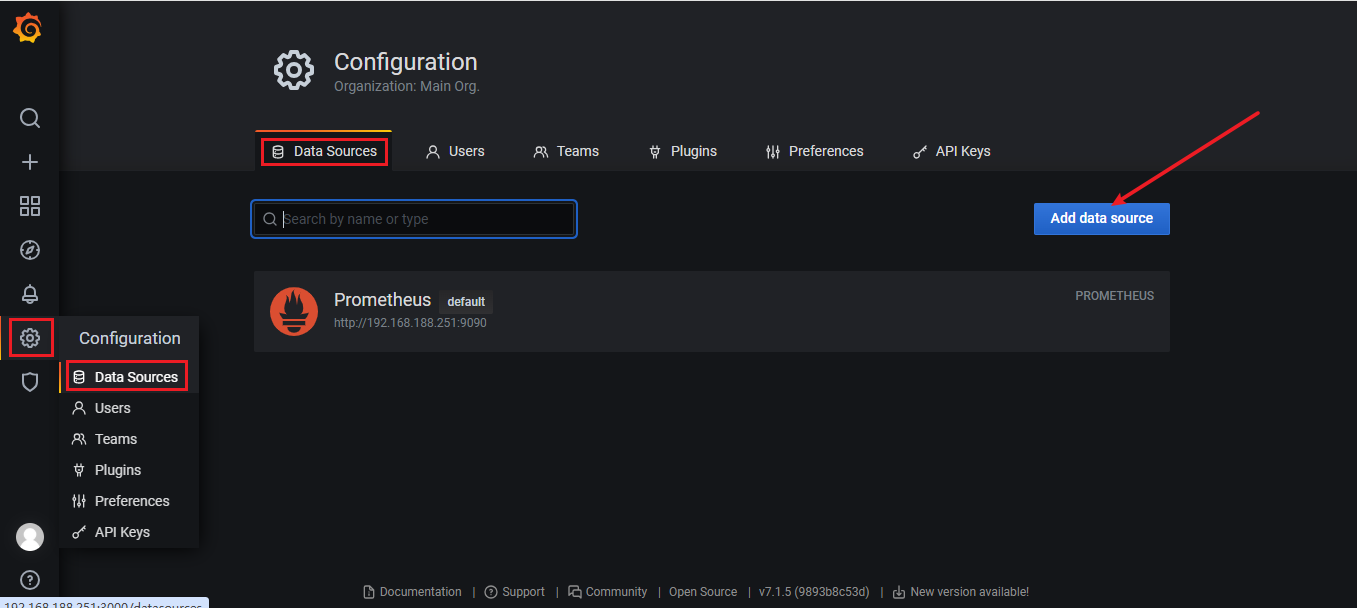
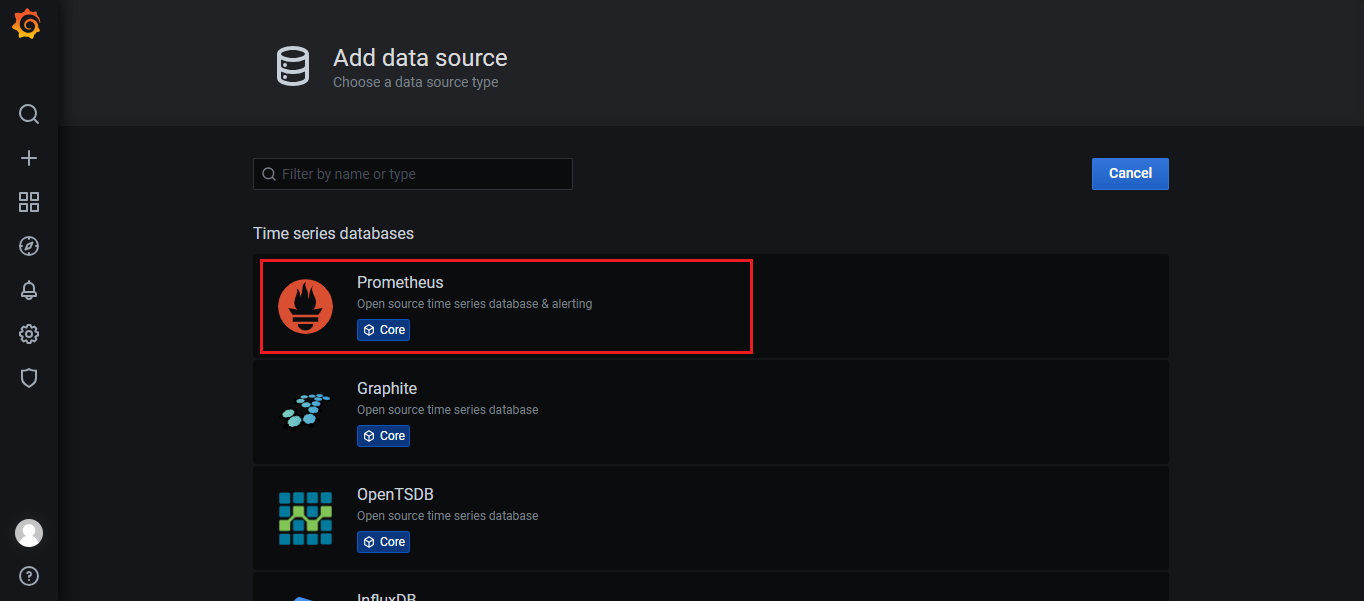
1、添加 Prometheus date:
2、添加 grafana 仪表盘 或下载对应 json文件:
13868windows_exporter for Prometheus Dashboard EN
12633Linux主机详情
11074Node Exporter Dashboard EN 20201010-StarsL.cn
7362MySQL Overview7、grafana账号、密码:
1、登录地址:
http://本机IP:3000
2、用户名:
admin
3、密码:
qwe123!@#三、客户端:
1、Linux客户端服务器 部署监控服务配置:
1、创建目录:
mkdir -p /home/docker-prometheus-node-exporter
2、进入相关目录、创建配置文件:
cd /home/docker-prometheus-node-exporter
vim docker-compose.yml
version: '3.2'
services:
nodeexporter:
image: 192.168.188.251:8081/node_exporter/node_exporter:v1.8.2
container_name: nodeexporter
volumes:
- ./proc:/host/proc:ro
- ./sys:/host/sys:ro
- ./:/rootfs:ro
environment:
TZ: Asia/Shanghai
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)'
labels:
org.label-schema.group: "monitoring"
restart: always
network_mode: host3、启动服务:
cd /root/docker-prometheus # (有 docker-compose.yml 文件的目录下部署服务)
docker-compose up -d # 启动服务
docker-compose stop # 停止服务
docker-compose down -v # 删除服务,先停止后才能删除
docker-compose restart # 重启服务,会重新加载配置文件
docker-compose ps # 查看服务是否正常启动
docker-compose ps -a # 查看服务是否正常启动
netstat -tlun | grep 8080 # 查看端口是否正常启动
netstat -tlun | grep 9100 # 查看端口是否正常启动4、防火墙放行:
systemctl status firewalld # 查看防火墙是否开启:
firewall-cmd --zone=public --add-port=8080/tcp --permanent # --zone=public 表示作用域为公共区域,--add-port=8080/tcp 表示添加 TCP 协议的 8080 端口,--permanent 表示永久生效
firewall-cmd --zone=public --add-port=9100/tcp --permanent # 放行9100端口
firewall-cmd --reload # 防火墙重新加载配置,使配置生效2、Windows Server服务器 部署监控服务配置:
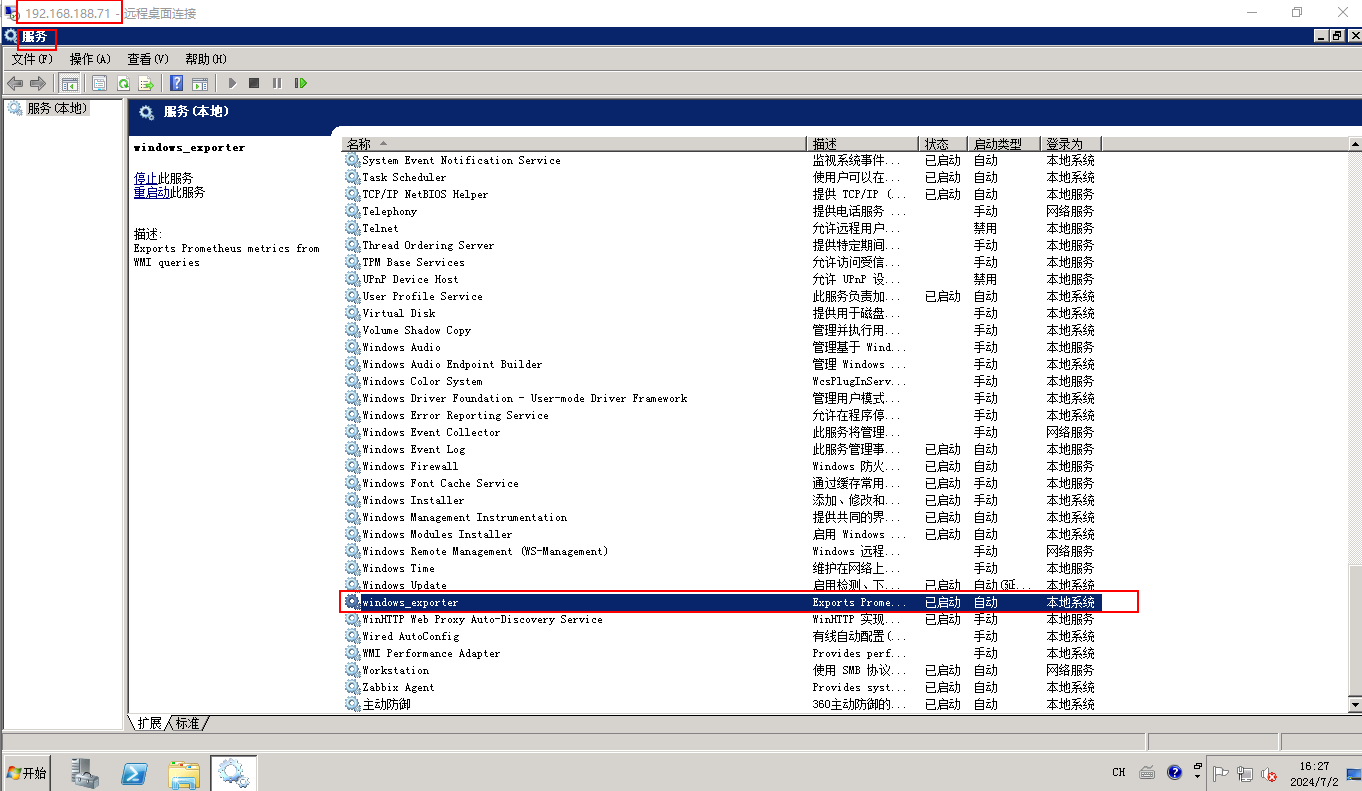
1、安装 windows_exporter-0.14.0-amd64.msi 被监控端:
windows server 2008 r2 ---安装---> windows_exporter-0.14.0-amd64.msi
2、软件下载地址:
3、在服务中查看 windows_exporter 服务 默认端口为 9182: